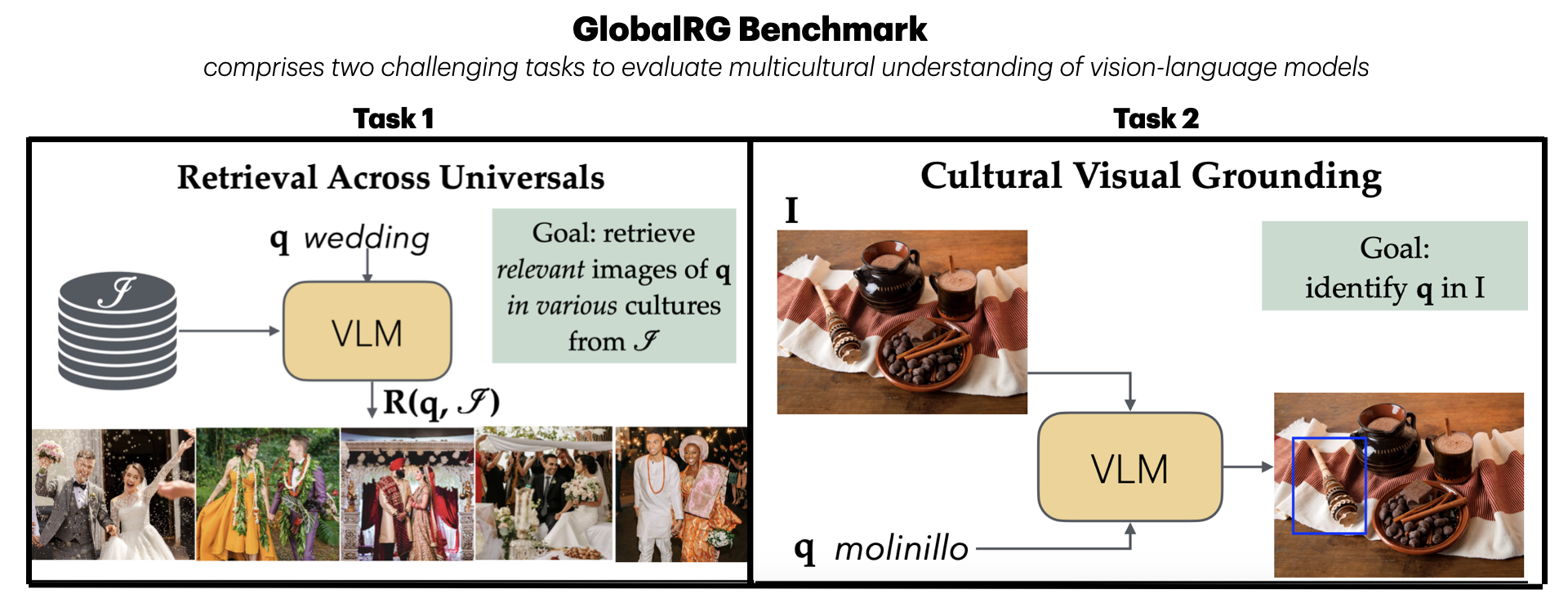
Let \( Q = \{q_1, q_2, \ldots, q_n\} \) be a set of textual queries representing universal concepts, and \( I = \{I_1, I_2, \ldots, I_m\} \) the set of images from different cultures. Given a query \( q \in Q \), the goal is to retrieve a ranked list of images \( R(q, I) = \{I_{r1}, I_{r2}, \ldots, I_{rk} \} \subset I \) that maximizes both relevance and cultural diversity.
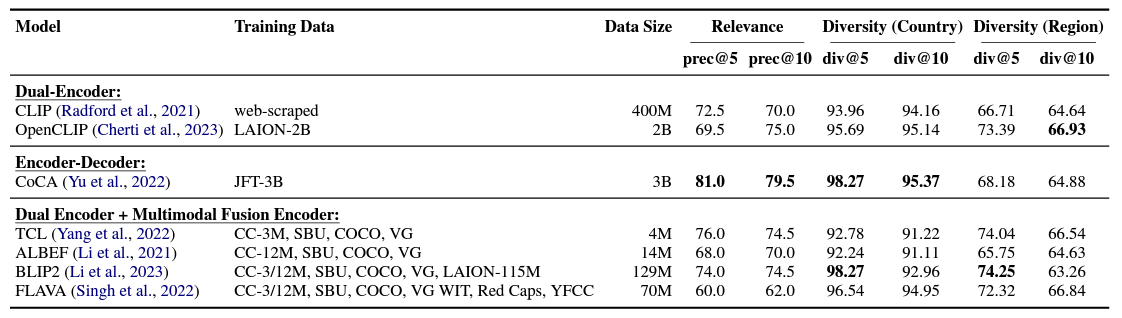
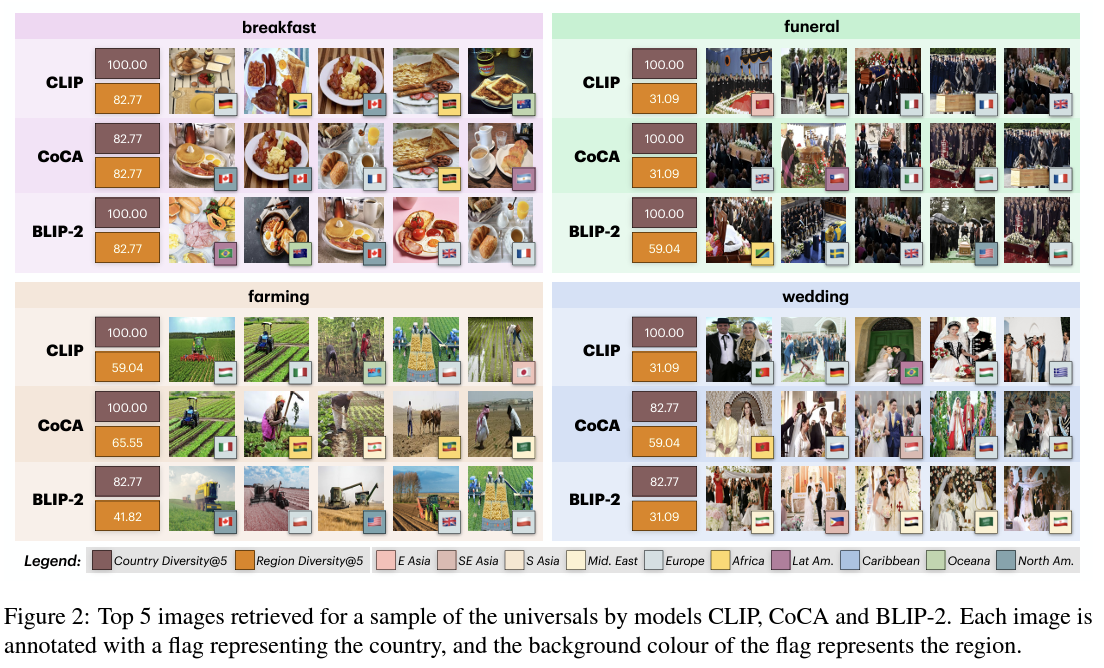
Relevance: \( \text{Rel}(q, I) \) refers to how well the image \( I \) matches the query \( q \) captured by the standard precision@k.
Diversity: \( \text{Div}(R(q, I)) \) measures the cultural diversity of the retrieved images using the formula,
\[
\text{diversity@k} = - \frac{1}{\log m} \sum_{i=1}^{m} p_i \log(p_i)
\]
where \( p_i \) is the proportion of images from the \( i \)-th culture in the top \( k \) retrieved images \( R(q) \),
and \( m \) is the total number of cultures in the top \( k \).
A high entropy value (∼ 100) indicates high diversity, retrieved images are well-distributed across different cultures.
Conversely, a low entropy value (∼ 0) indicates low diversity, retrieved images are biased towards specific cultures.